















みなさん、こんにちは。Red Hat OpenShift(以下OpenShift)のプリセールス、構築を担当している古野です。
はじめに
本連載では、OpenShift 環境の導入・運用・設計に携わるエンジニアに向けて、目的別・レベル別に構成図を描くための考え方と実践例を紹介しています。
今回含めて構成図に関するブログを3部構成で投稿しています。
| Vol. | テーマ | 詳細 |
| Vol.1 | 基礎編 | クラスタの基本要素とサーバ間の関係 |
| Vol.2 | VersionUp編 本記事 | バージョンアップクラスタの構成設計 |
| Vol.3 | DR編 | 災害対策環境の構成設計 |
前回のVol.1(基礎編)では、OpenShiftクラスタの基本構成やネットワーク構成の考え方を紹介しました。
今回のVol.2では、バージョンアップ時のクラスタ構成設計にフォーカスします。
OpenShiftのバージョンアップそのものの仕組みや戦略については、「OpenShift アップグレード 虎の巻」に非常に詳しくまとまっています。本記事では、その戦略を「インフラ構成としてどう具体化するか」、「構成図に落とし込むとどうなるのか」に焦点を当てます。
なぜバージョンアップの構成設計が重要なのか
OpenShiftはおよそ4〜6ヶ月ごとに新しいマイナーバージョンがリリースされ、偶数バージョン(EUS)でも最長36ヶ月のサポートです。つまり、構築時点でバージョンアップを前提としたクラスタ構成を設計しておく必要があります。
バージョンアップのための構成検討ポイントは以下が挙げられます。
- クラスタは何面必要か?(1面? 2面?)
- LB・DNSの切り替え設計はどうするか?
-
Mirror Registryはバージョンごとに分けるか?
- バージョンアップ用の追加リソースをどこに確保するか?
これらのポイントは、バージョンアップの際の切り替え時間をどれだけ確保できるか、によっても変わってきますので、OpenShift上に載せるアプリケーションの停止可能時間に応じてクラスタを分けることも検討のポイントとなってくると考えます。
また、DBのデータやコンテナイメージなどアプリケーションの稼働に必要なデータをクラスタの外に配置することでOpenShiftクラスタとデータ領域が疎結合となりますので、切り替えにおけるダウンタイムの短縮につながります。
一概にこの構成がベストとは言い切れませんので、運用・管理の手間やインフラ層のコストのバランスから構成を案件に応じて検討いただければと思います。
バージョンアップ戦略と構成パターン
OpenShiftのバージョンアップには大きく3つの戦略があります。それぞれの戦略に対して、どのような構成図を描くかを整理します。
1). In-place アップグレード構成
概要:単一クラスタ上でOTAアップグレードを実行する最もシンプルな方式です。クラスタ内のCluster Version Operatorがアップグレードの実行・管理を行い、Cluster Operator → Control Plane → Worker Nodeの順に1台ずつアップグレードが実行されます。
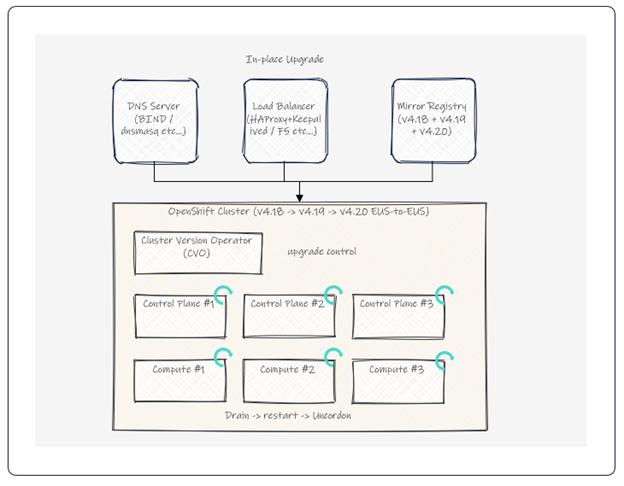
図1:In-place アップグレード構成例
・Computeノード台数の余裕:アップグレード中はノードが1台ずつ再起動(Drain → 再起動 → Uncordon)されるため、N+1以上のComputeノードを確保し、Podの退避先を用意する。
・PodDisruptionBudget(PDB)の設定:アプリケーションのPodが同時にすべて停止しないよう maxUnavailable を設定する。
・Inter-Pod Anti-Affinity:同じアプリのPodが1つのノードに集中しないようスケジューリングを制御する。
・Mirror Registry:非接続環境では、アップグレード先バージョンのイメージを事前にミラーしておく(現行バージョン+アップグレード先バージョンの両方を格納)。
| 項目 | 内容 |
| メリット | 追加リソース不要、構成がシンプル |
| デメリット | アプリへの影響を完全に回避できない、ロールバックが困難 |
| 推奨ケース | 開発/検証環境、サービス断許容のある環境 |
表1:In-place アップグレードのメリット・デメリット
2). Blue/Green アップグレード構成 ★本番環境推奨
概要:複数クラスタを準備し、LBやDNSでトラフィックを切り替えながらアップグレードする方式です。クラスターの上段にあるネットワーク装置(DNS/LBなど)でアップグレード前に対象のクラスターをサービスアウトし、アプリの可用性に影響の出ない状態でクラスターをアップグレードしていきます。本番環境で最も採用されるパターンです。
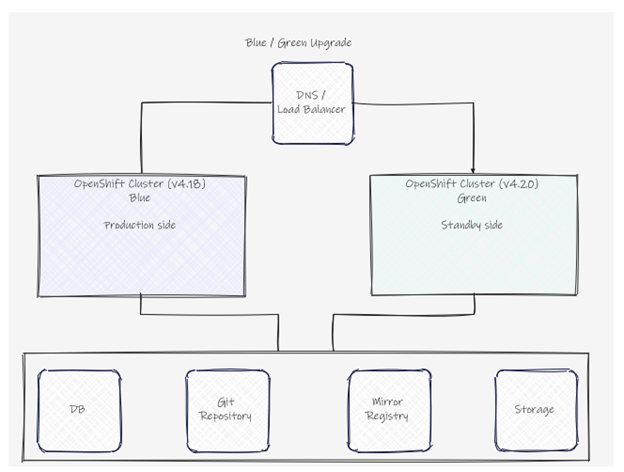
図2:Blue/Green アップグレード構成例
<切り替え方式の選択肢>
| 切り替え方式 | 切り替え速度 | 構成の複雑さ | 利用可能な環境 |
| DNS切り替え(推奨) | TTL依存(数十秒〜数分) | 低い | インターネット/社内NW両方 |
| LB切り替え | 即時 | 中程度(SPOF注意) | インターネット/社内NW両方 |
表2:Blue/Green切り替え方式の例
・データの外部化:Blue/Green構成では、ステートフルなデータ(DB、ファイルストレージ等)をクラスタ外部に切り出す。PVはクラスタ内に閉じるため、クラスタ間でのデータ共有には向かない。
・GitOps(ArgoCD)の活用:両クラスタに同一のマニフェストをデプロイするため、GitOpsによる宣言的管理が必須。新バージョンのクラスタにも同じGitリポジトリからデプロイすることで環境差異を防ぐ。
・Mirror Registryの共有:Blue/Green両方のクラスタが参照できる位置にMirror Registryを配置する(非接続環境の場合)。
| 項目 | 内容 |
| メリット | サービス断を最小化、ロールバック容易、本番SLAを維持 |
| デメリット | クラスタ2面分のリソースが必要、データ外部化の設計が必要 |
| 推奨ケース | 本番環境、高可用性が求められるシステム |
表3:Blue/Green アップグレードのメリット・デメリット
3). Recreate アップグレード構成
概要:旧バージョンクラスタとは別に新バージョンのクラスタを新規構築し、アプリケーションを移行後に旧クラスタを廃棄する方式です。OpenShiftはKubernetesの宣言的な構成管理を行うため、クラスターのあるべき姿をコード化することで複数クラスターに対して同様の設定を投入しやすくなり、クラスター再作成のプロセスを大きく効率化できます。
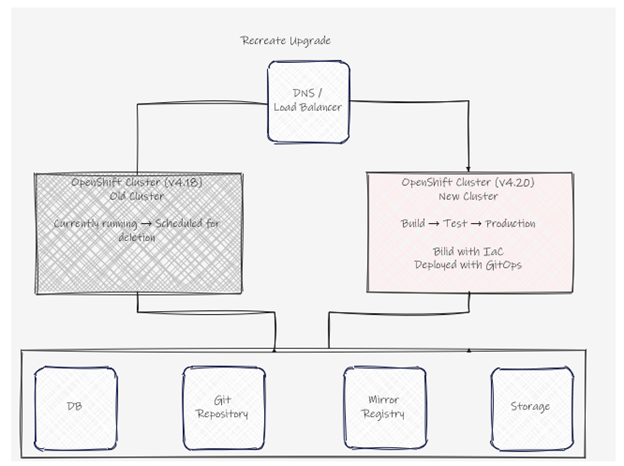
図3:Recreate アップグレード構成例
・IaC(Infrastructure as Code)の導入:クラスタの構築自体をTerraform/Ansible等でコード化し、繰り返し実行可能にする。
・アップグレードパスの考慮が不要:新規構築のため、Before→Afterのバージョン互換性を気にする必要がない。GAされた時点で即座に新バージョンを構築できる。
・Operatorのバージョン管理も簡素化:新クラスタに新バージョンのOperatorをインストールするだけでよく、既存Operatorのアップグレード手順の検証が不要。
・ステートのリフレッシュ:新バージョンを新規構築することで、同一環境を長期運用することで蓄積されるステートの想定外の事象発生を軽減する。
| 項目 | 内容 |
| メリット | 環境のリフレッシュ、アップグレードパス不要、IaC化の推進 |
| デメリット | クラスタ再構築の自動化が前提、アプリ移行の検証が必要 |
| 推奨ケース | IaC/GitOpsが成熟した組織、クラウド環境 |
表4:Recreate アップグレードのメリット・デメリット
各戦略の比較まとめ
以下が各アップグレード戦略の比較となりますが、個人的にはRecreateがおすすめです。Blue/GreenはIn-Paceを2面で実施していることもあり、切り替えは早いですが、バージョンアップの際の手間がどうしてもかかってしまうので作り直しては切り替え、を繰り替える方式のほうがバージョンアップ前のリソースの影響が少ない印象です。ただし、毎度作り直すことによる手間を削減するために構築やアプリケーション移行のIaC化を考慮する必要がありますので、少し腰が重くなってしまう点も出てくるかと思います。
| 観点 | In-place | Blue/Green | Recreate |
| 必要なクラスタ数 | 1面 | 2面 | 1面(+構築中の1面) |
| サービス断リスク | 中〜高 | 低 | 低 |
| ロールバック容易性 | 困難 | 容易 | 容易 |
| 追加リソースコスト | 低 | 高 | 中(一時的) |
| IaC/GitOps成熟度 | 不要 | 推奨 | 必須 |
| アップグレードパス考慮 | 必要 | 必要 | 不要 |
| 推奨環境 | 開発/検証 | 本番 | IaC成熟環境 |
表5:バージョンアップ戦略の比較
非接続環境でのMirror Registry設計
多くのエンタープライズ環境では、クラスタがインターネットに接続できない非接続(Air-Gap/Disconnected)環境で運用されます。この場合、バージョンアップに必要なイメージをMirror Registryに事前ミラーする設計が必要です。
<設計のポイント>
・oc mirror コマンドで必要なイメージセットをダウンロードし、物理メディア等で非接続環境に転送する。
・EUS-to-EUSの場合、中間バージョン(奇数)のイメージも必要になるため、Mirror Registryの容量計画に注意する。
・Operatorのカタログイメージも忘れずにミラーする。
・Blue/Green構成の場合はBlue/Green両方のクラスタが参照できる位置にMirror Registryを配置する。
まとめ
バージョンアップの構成設計は、クラスタを構築する時点から考えておくべきテーマです。構築後に「やっぱりBlue/Greenにしたい」と思っても、データの外部化やLB/DNSの設計変更など、大きな手戻りが発生する可能性があります。
IaCについては一足飛びに進めるのは難しいと思いますので、まずは構成を決めるところからスタートして徐々に人の手を介さずに手間をかけずにバージョンアップができる基盤へ成長させていくとスタート時点のハードルを下げられるかと思います。
バージョンアップ戦略の選択は、アプリケーションの可用性要件、インフラリソースの余裕、組織のIaC/GitOps成熟度を総合的に判断して決定しましょう。
また、バージョンアップ時に削除・変更されるAPIがないか、アプリケーションや監視への影響がないかを調査する工程はどの戦略をとっても必要になりますので、実際のバージョンアップ作業では、クラスタのバージョンアップ作業よりも調査やテストに時間を要します。
これらの作業をいかに効率化していけるか、という点もバージョンアップ戦略になってくると考えます。
次回、Vol.3(DR編)では、災害対策環境の構成設計について触れていきます。バージョンアップ構成と組み合わせることで、より堅牢なOpenShift環境を実現できますので、ぜひあわせてご覧ください。











